6 Logistic regression
Logistic regression is very similar to linear regression, but applied to classification problems. In this chpater our idea is to treat it as the simplest example of a neural network instead of using other methods. The code we developped in the last chapter will be used extensively.
6.1 Basic idea
Assume that we have a binary classfification problem with \(N\) features. Our model starts from the logit instead of the label \(y\) itself.
\[ logit(y)=\theta_0+\sum_{j=1}^N\theta_jx_j. \]
The logit function is used to describe the logorithm of the binary odds. The odd ratio is the ratio between the probability of success and the probability of failure. Assume the probability of success is \(p\). Then
\[ oddratio(p)=\frac{p}{1-p},\quad logit(p)=z = \log\left(\frac{p}{1-p}\right). \] We could solve the logit function, and get its inverse: the function is the Sigmoid function. Once we have the logit value, we could use it to get the probability. \[ p=\sigma(z)=\frac{1}{1+\mathrm{e}^{-z}}. \]
Therefore the model for Logistic regression is as follows:
\[ p=\sigma(L(x))=\sigma\left(\theta_0+\sum_{j=1}^n\theta_jx_j\right)=\sigma\left(\Theta \hat{x}^T\right). \]
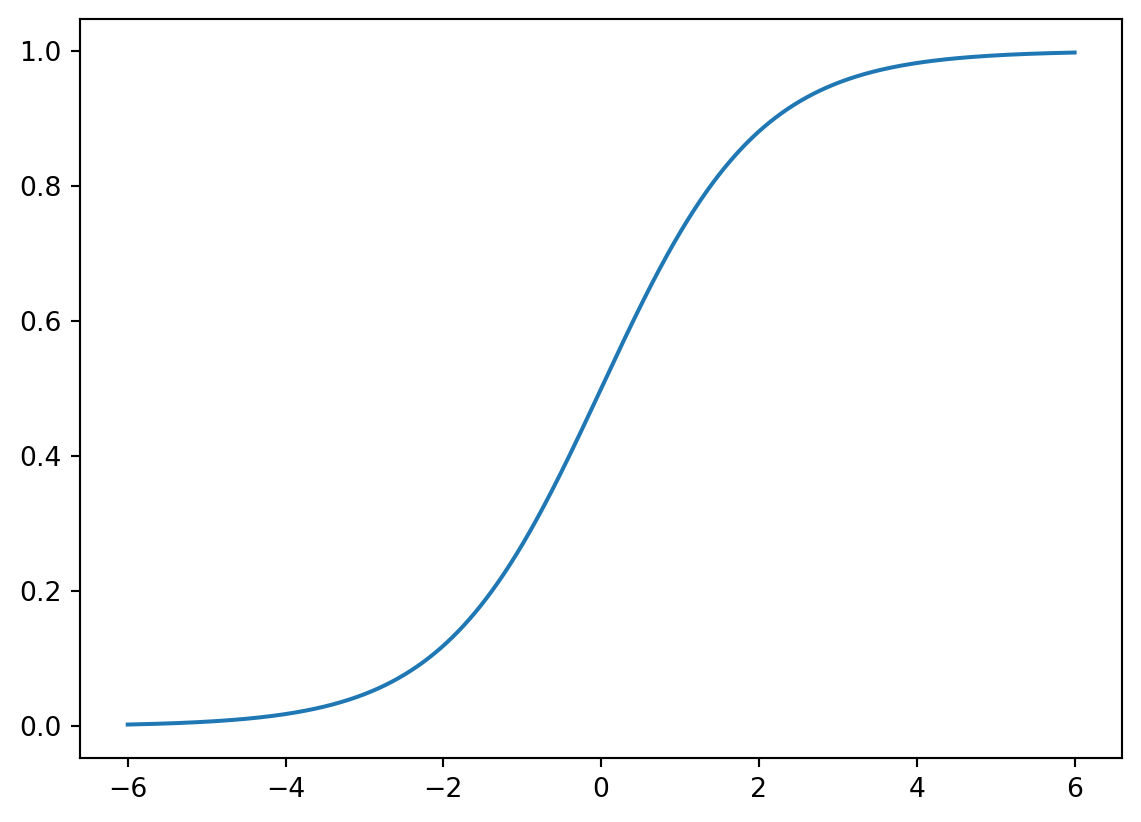
6.1.1 Sigmoid function
The Sigmoid function is defined as follows:
\[ \sigma(z)=\frac{1}{1+\mathrm{e}^{-z}}. \] The graph of the function is shown below.
The main properties of \(\sigma\) are listed below as a Lemma.
Lemma 6.1 The Sigmoid function \(\sigma(z)\) satisfies the following properties.
- \(\sigma(z)\rightarrow \infty\) when \(z\mapsto \infty\).
- \(\sigma(z)\rightarrow -\infty\) when \(z\mapsto -\infty\).
- \(\sigma(0)=0.5\).
- \(\sigma(z)\) is always increasing.
- \(\sigma'(z)=\sigma(z)(1-\sigma(z))\).
Solution. We will only look at the last one.
\[ \begin{split} \sigma'(z)&=-\frac{(1+\mathrm e^{-z})'}{(1+\mathrm e^{-z})^2}=\frac{\mathrm e^{-z}}{(1+\mathrm e^{-z})^2}=\frac{1}{1+\mathrm e^{-z}}\frac{\mathrm e^{-z}}{1+\mathrm e^{-z}}\\ &=\sigma(z)\left(\frac{1+\mathrm e^{-z}}{1+\mathrm e^{-z}}-\frac{1}{1+\mathrm e^{-z}}\right)=\sigma(z)(1-\sigma(z)). \end{split} \]
6.1.2 Gradient descent
We would like to use Gradient descent to sovle Logistic regression problems. For binary classification problem, the cost function is defined to be
\[ J(\Theta)=-\frac1m\sum_{i=1}^m\left[y^{(i)}\log(p^{(i)})+(1-y^{(i)})\log(1-p^{(i)})\right]. \] Here \(m\) is the number of data points, \(y^{(i)}\) is the labelled result (which is either \(0\) or \(1\)), \(p^{(i)}\) is the predicted value (which is between \(0\) and \(1\)).
Note
The algorithm gets its name since we are using the gradient to find a direction to lower our height.
6.1.3 The Formulas
Theorem 6.1 The gradient of \(J\) is computed by
\[ \nabla J =\frac1m(\textbf{p}-\textbf{y})^T\hat{\textbf{X}}. \tag{6.1}\]
Click for details.
Proof. The formula is an application of the chain rule for the multivariable functions.
\[ \begin{split} \dfrac{\partial p}{\partial \theta_k}&=\dfrac{\partial}{\partial \theta_k}\sigma\left(\theta_0+\sum_{j=1}^n\theta_jx_j\right)=\dfrac{\partial}{\partial \theta_k}\sigma(L(\Theta))\\ &=\sigma(L)(1-\sigma(L))\dfrac{\partial}{\partial \theta_k}\left(\theta_0+\sum_{j=1}^n\theta_jx_j\right)\\ &=\begin{cases} p(1-p)&\text{ if }k=0,\\ p(1-p)x_k&\text{ otherwise}. \end{cases} \end{split} \] Then
\[ \nabla p = \left(\frac{\partial p}{\partial\theta_0},\ldots,\frac{\partial p}{\partial\theta_n}\right) = p(1-p)\hat{x}. \]
Then
\[ \nabla \log(p) = \frac{\nabla p}p =\frac{p(1-p)\hat{x}}{p}=(1-p)\hat{x}. \]
\[ \nabla \log(1-p) = \frac{-\nabla p}{1-p} =-\frac{p(1-p)\hat{x}}{1-p}=-p\hat{x}. \]
Then
\[ \begin{split} \nabla J& = -\frac1m\sum_{i=1}^m\left[y^{(i)}\nabla \log(p^{(i)})+(1-y^{(i)})\nabla \log(1-p^{(i)})\right]\\ &=-\frac1m\sum_{i=1}^m\left[y^{(i)}(1-p^{(i)})\hat{x}^{(i)}+(1-y^{(i)})(-p^{(i)}\hat{x}^{(i)})\right]\\ &=-\frac1m\sum_{i=1}^m\left[(y^{(i)}-p^{(i)})\hat{x}^{(i)}\right]. \end{split} \]
We write \(\hat{x}^{(i)}\) as row vectors, and stack all these row vectors vertically. What we get is a matrix \(\hat{\textbf X}\) of the size \(m\times (1+n)\). We stack all \(y^{(i)}\) (resp. \(p^{(i)}\)) vectically to get the \(m\)-dim column vector \(\textbf y\) (resp. \(\textbf p\)).
Using this notation, the previous formula becomes
\[ \nabla J =\frac1m(\textbf{p}-\textbf{y})^T\hat{\textbf{X}}. \]
After the gradient can be computed, we can start to use the gradient descent method. Note that, although \(\Theta\) are not explicitly presented in the formula of \(\nabla J\), this is used to modify \(\Theta\):
\[ \Theta_{s+1} = \Theta_s - \alpha\nabla J. \]
Note
If you directly use library, like sklearn or PyTorch, they will handle the concrete computation of these gradients.
6.2 Regularization
6.2.1 Three types of errors
Every estimator has its advantages and drawbacks. Its generalization error can be decomposed in terms of bias, variance and noise. The bias of an estimator is its average error for different training sets. The variance of an estimator indicates how sensitive it is to varying training sets. Noise is a property of the data.
6.2.2 Underfit vs Overfit
When fit a model to data, it is highly possible that the model is underfit or overfit.
Roughly speaking, underfit means the model is not sufficient to fit the training samples, and overfit means that the models learns too many noise from the data. In many cases, high bias is related to underfit, and high variance is related to overfit.
The following example is from the sklearn guide. Although it is a polynomial regression example, it grasps the key idea of underfit and overfit.
6.2.3 Learning curves (accuracy vs training size)
A learning curve shows the validation and training score of an estimator for varying a key hyperparameter. In most cases the key hyperparameter is the training size or the number of epochs. It is a tool to find out how much we benefit from altering the hyperparameter by training more data or training for more epochs, and whether the estimator suffers more from a variance error or a bias error.
sklearn provides sklearn.model_selection.learning_curve() to generate the values that are required to plot such a learning curve. However this function is just related to the sample size. If we would like to talk about epochs, we need other packages.
Let us first look at the learning curve about sample size. The official document page is here. The function takes input estimator, dataset X, y, and an arry-like argument train_sizes. The dataset (X, y) will be split into pieces using the cross-validation technique. The number of pieces is set by the argument cv. The default value is cv=5. For details about cross-validation please see Section 2.2.5.
Then the model is trained over a random sample of the training set, and evaluate the score over the test set. The size of the sample of the training set is set by the argument train_sizes. This argument is array-like. Therefore the process will be repeated several times, and we can see the impact of increasing the training size.
The output contains three pieces. The first is train_sizes_abs which is the number of elements in each training set. This output is mainly for reference. The difference between the output and the input train_sizes is that the input can be float which represents the percentagy. The output is always the exact number of elements.
The second output is train_scores and the third is test_scores, both of which are the scores we get from the training and testing process. Note that both are 2D numpy arrays, of the size (number of different sizes, cv). Each row is a 1D numpy array representing the cross-validation scores, which is corresponding to a train size. If we want the mean as the cross-validation score, we could use train_scores.mean(axis=1).
After understanding the input and output, we could plot the learning curve. We still use the horse colic as the example. The details about the dataset can be found here.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
filepath = "assests/datasets/horse_colic_clean.csv"
df = pd.read_csv(filepath)
X = df.iloc[:, :22].to_numpy().astype(float)
y = (df.iloc[:, 22]<2).to_numpy().astype(int)
SEED = 42
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=SEED)We use the model LogisticRegression. The following code plot the learning curve for this model.
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import MinMaxScaler
from sklearn.pipeline import Pipeline
clf = LogisticRegression(max_iter=1000)
steps = [('scalar', MinMaxScaler()),
('log', clf)]
pipe = Pipeline(steps=steps)
from sklearn.model_selection import learning_curve
import numpy as np
train_sizes, train_scores, test_scores = learning_curve(pipe, X_train, y_train,
train_sizes=np.linspace(0.1, 1, 20))
import matplotlib.pyplot as plt
plt.plot(train_sizes, train_scores.mean(axis=1), label='train')
plt.plot(train_sizes, test_scores.mean(axis=1), label='test')
plt.legend()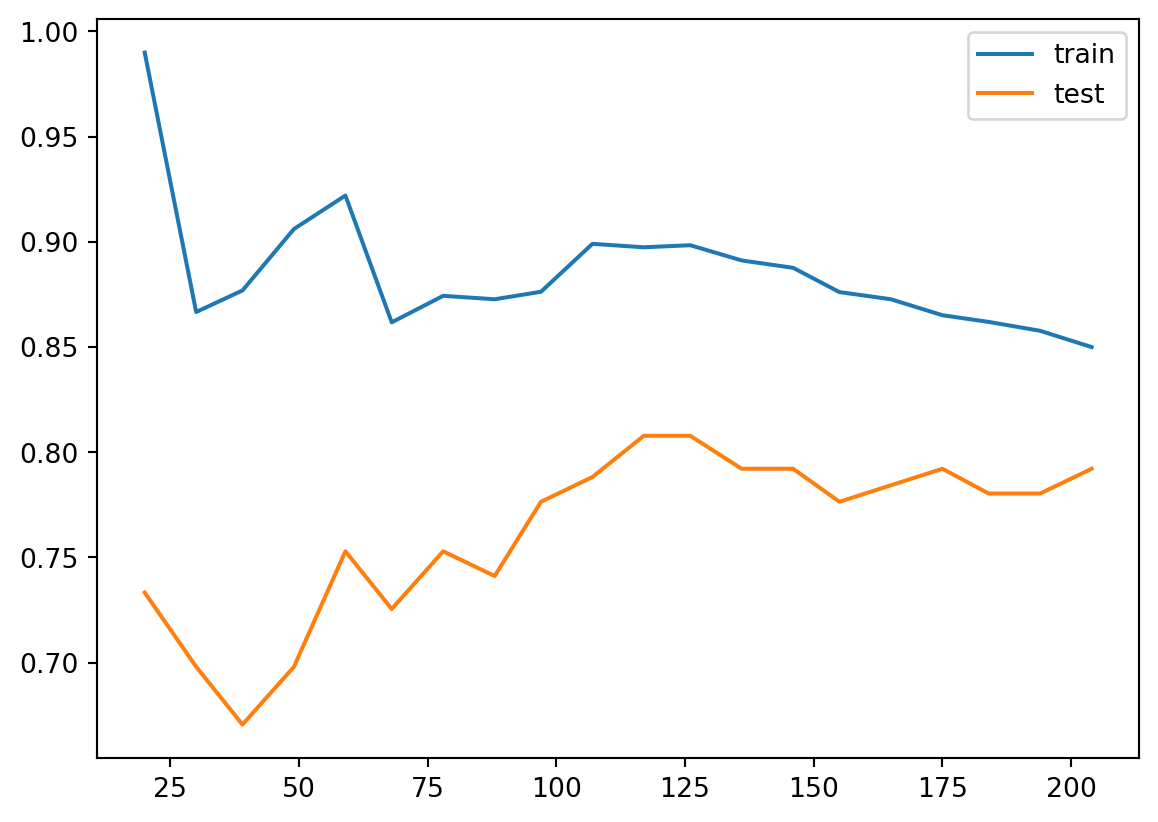
The learning curve is a primary tool for us to study the bias and variance. Usually
- If the two training curve and the testing curve are very close to each other, this means that the variance is low. Otherwise the variance is high, and this means that the model probabily suffer from overfitting.
- If the absolute training curve score is high, this means that the bias is low. Otherwise the bias is high, and this means that the model probabily suffer from underfitting.
In the above example, although regularization is applied by default, you may still notice some overfitting there.
6.2.4 Regularization
Regularization is a technique to deal with overfitting. Here we only talk about the simplest method: ridge regression, also known as Tikhonov regularizaiton. Because of the formula given below, it is also called \(L_2\) regularization. The idea is to add an additional term \(\dfrac{\alpha}{2m}\sum_{i=1}^m\theta_i^2\) to the original cost function. When training with the new cost function, this additional term will force the parameters in the original term to be as small as possible. After finishing training, the additional term will be dropped, and we use the original cost function for validation and testing. Note that in the additional term \(\theta_0\) is not presented.
The hyperparameter \(\alpha\) is the regularization strength. If \(\alpha=0\), the new cost function becomes the original one; If \(\alpha\) is very large, the additional term dominates, and it will force all parameters to be almost \(0\). In different context, the regularization strength is also given by \(C=\dfrac{1}{2\alpha}\), called inverse of regularization strength.
6.2.4.1 The math of regularization
Theorem 6.2 The gradient of the ridge regression cost function is
\[ \nabla J=\frac1m(\textbf{p}-\textbf{y})^T\hat{\textbf{X}}+\frac{\alpha}{m}\Theta. \]
Note that \(\Theta\) doesn’t contain \(\theta_0\), or you may treat \(\theta_0=0\).
The computation is straightforward.
6.2.4.2 The code
Regularization is directly provided by the logistic regression functions.
- In
LogisticRegression, the regularization is given by the argumentpenaltyandC.penaltyspecifies the regularizaiton method. It isl2by default, which is the method above.Cis the inverse of regularization strength, whose default value is1. - In
SGDClassifier, the regularization is given by the argumentpenaltyandalpha.penaltyis the same as that inLogisticRegression, andalphais the regularization strength, whose default value is0.0001.
Let us see the above example.
clf = LogisticRegression(max_iter=1000, C=0.1)
steps = [('scalar', MinMaxScaler()),
('log', clf)]
pipe = Pipeline(steps=steps)
from sklearn.model_selection import learning_curve
import numpy as np
train_sizes, train_scores, test_scores = learning_curve(pipe, X_train, y_train,
train_sizes=np.linspace(0.1, 1, 20))
import matplotlib.pyplot as plt
plt.plot(train_sizes, train_scores.mean(axis=1), label='train')
plt.plot(train_sizes, test_scores.mean(axis=1), label='test')
plt.legend()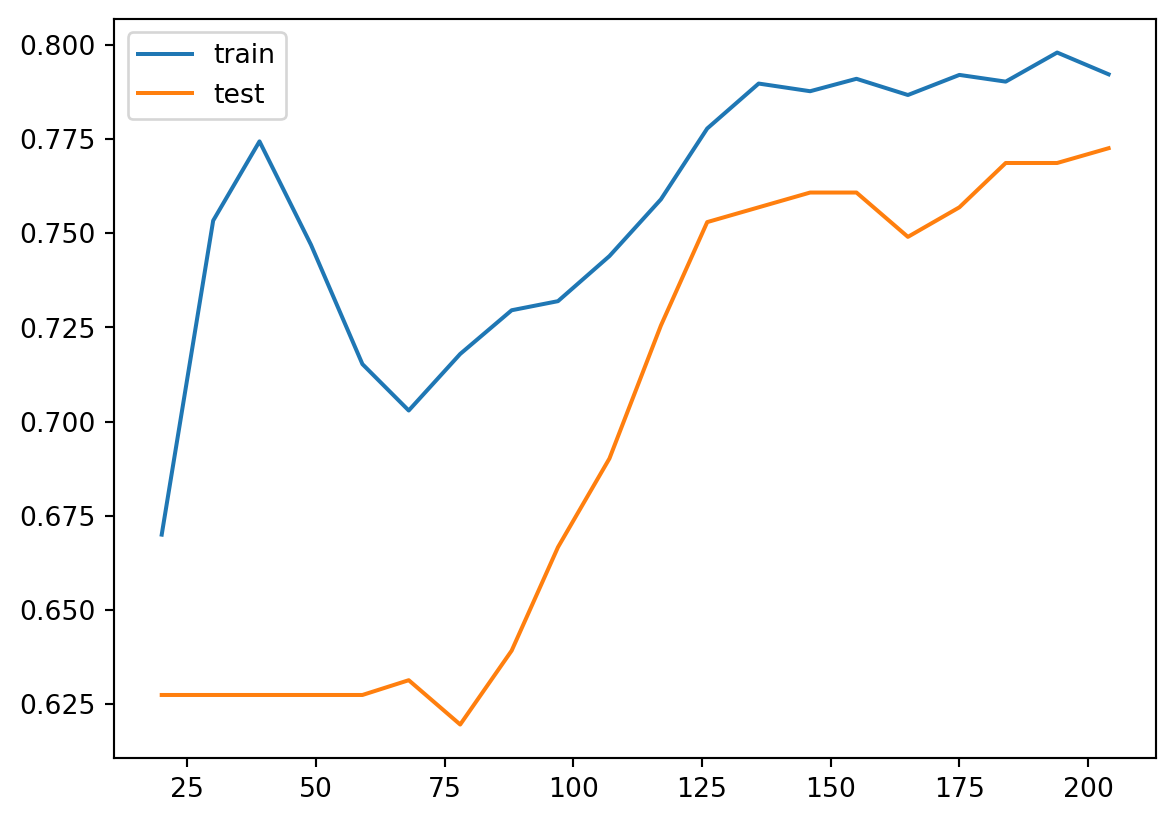
After we reduce C from 1 to 0.1, the regularization strength is increased. Then you may find that the gap between the two curves are reduced. However the overall performace is also reduced, from 85%~90% in C=1 case to around 80% in C=0.1 case. This means that the model doesn’t fit the data well as the previous one. Therefore this is a trade-off: decrease the variance but increase the bias.
6.3 Neural network implement of Logistic regression
In the previous sections, we use gradient descent to run the Logistic regression model. We mentioned some important concepts, like epochs, mini-batch, etc.. We are going to use PyTorch to implement it. We will reuse many codes we wrote in the previous chapter.
6.3.1 Example
We still use the horse colic dataset as an example. We first prepare the dataset.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
filepath = "assests/datasets/horse_colic_clean.csv"
df = pd.read_csv(filepath)
X = df.iloc[:, :22].to_numpy().astype(float)
y = (df.iloc[:, 22]<2).to_numpy().astype(int)
SEED = 42
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=SEED)We need to perform normalization before throwing the data into the model. Here we use the MinMaxScaler() from sklearn package.
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
X_train = mms.fit_transform(X_train, y_train)
X_test = mms.transform(X_test)Then we write a Dataset class to build the dataset and create the dataloaders. Since the set is already split, we don’t need to random_split here.
import torch
from torch.utils.data import Dataset, DataLoader
class MyData(Dataset):
def __init__(self, X, y):
self.X = torch.tensor(X, dtype=float)
self.y = torch.tensor(y, dtype=float).reshape(-1, 1)
def __getitem__(self, index):
return (self.X[index], self.y[index])
def __len__(self):
return len(self.y)
train_set = MyData(X_train, y_train)
val_set = MyData(X_test, y_test)
train_loader = DataLoader(train_set, batch_size=32, shuffle=True)
val_loader = DataLoader(val_set, batch_size=32)In the following code, we first set up the original model.
import torch.nn as nn
from torch.nn.modules import Linear
class LoR(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.linear = Linear(in_features=22, out_features=1, dtype=float)
self.activation = nn.Sigmoid()
def forward(self, X):
# pred = self.activation(self.linear(X))
pred = self.linear(X)
# return (pred >= 0).float()
return predThen we run our regular training loop.
import time
import matplotlib.pyplot as plt
from torch.optim import SGD
from torch.nn import BCEWithLogitsLoss
model = LoR()
optim = SGD(model.parameters(), lr=0.2)
loss_fn = BCEWithLogitsLoss()
n_epochs = 30
class Meter:
def __init__(self, total=0.0, count=0, value=0.0):
self.total = total
self.count = count
self.value = value
self.avg = self.total / self.count if self.count > 0 else 0.0
def update(self, value, n=1):
self.value = value
self.total += value * n
self.count += n
self.avg = self.total / self.count if self.count > 0 else 0.0
history = {'loss': [], 'acc': [], 'loss_test': [], 'acc_test': []}
for epoch in range(n_epochs):
monitor_loss = Meter()
monitor_loss_test = Meter()
monitor_acc = Meter()
monitor_acc_test = Meter()
monitor_time = Meter()
for i, (X_batch, y_batch) in enumerate(train_loader):
model.train()
t0 = time.perf_counter()
optim.zero_grad()
p = model(X_batch)
loss = loss_fn(p, y_batch)
loss.backward()
optim.step()
t1 = time.perf_counter()
with torch.no_grad():
pred = (p>0).to(torch.long)
acc = (pred == y_batch).to(torch.float).mean().item()
monitor_acc.update(acc, n=X_batch.shape[0])
monitor_loss.update(loss.item(), n=X_batch.shape[0])
monitor_time.update(t1-t0, n=1)
print(
f'epoch: {epoch}, batch: {i+1}/{len(train_loader)} '
f'time: {monitor_time.value: .4f} ({monitor_time.total: .4f}) '
f'loss: {monitor_loss.value: .4f} ({monitor_loss.avg: .4f}) '
f'acc: {monitor_acc.value: .2f} ({monitor_acc.avg: .2f})'
)
history['loss'].append(monitor_loss.avg)
history['acc'].append(monitor_acc.avg)
with torch.no_grad():
model.eval()
for X_batch_test, y_batch_test in val_loader:
p = model(X_batch_test)
loss_test = loss_fn(p, y_batch_test)
monitor_loss_test.update(loss_test.item(), n=X_batch_test.shape[0])
pred_test = (p>0).to(torch.int)
acc_test = ( pred_test == y_batch_test).to(torch.float).mean().item()
monitor_acc_test.update(acc_test, n=X_batch_test.shape[0])
print(
f'test epoch {epoch} '
f'test loss: {monitor_loss_test.avg: .4f} '
f'test acc: {monitor_acc_test.avg: .2f}'
)
history['loss_test'].append(monitor_loss_test.avg)
history['acc_test'].append(monitor_acc_test.avg)
fig, axs = plt.subplots(1, 2)
fig.set_size_inches((10,3))
axs[0].plot(history['loss'], label='training_loss')
axs[0].plot(history['loss_test'], label='testing_loss')
axs[0].legend()
axs[1].plot(history['acc'], label='training_acc')
axs[1].plot(history['acc_test'], label='testing_acc')
axs[1].legend()
axs[0].set_title('Loss');
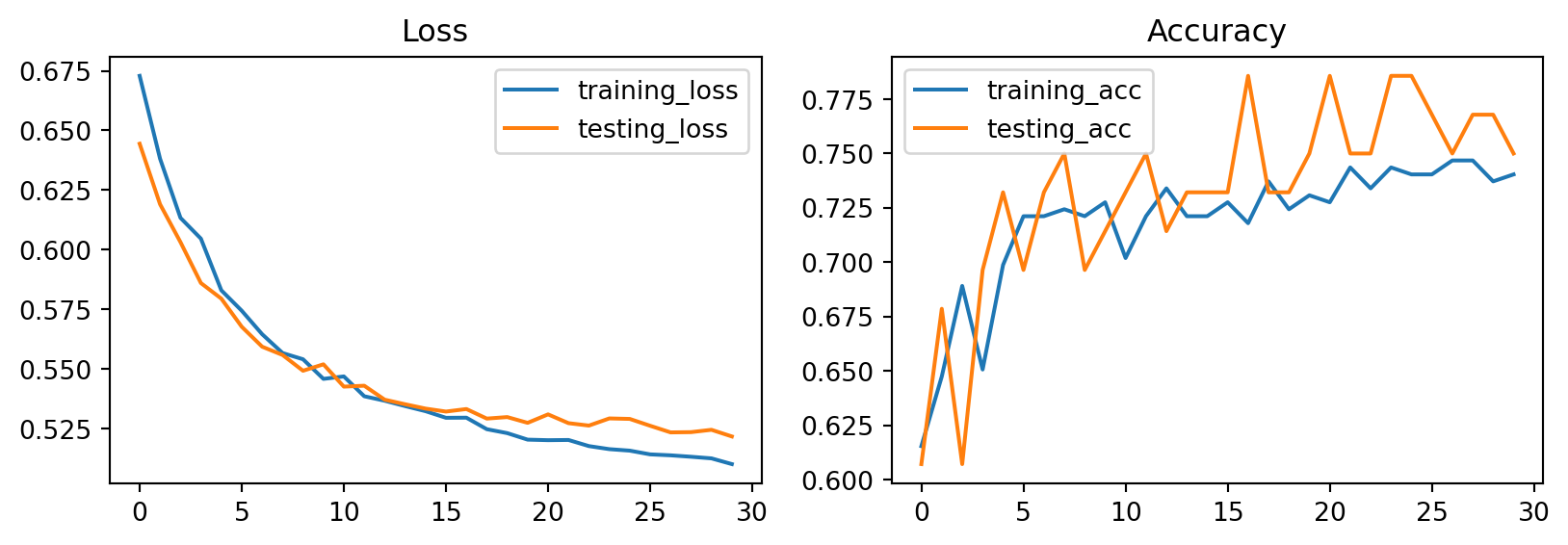
axs[1].set_title('Accuracy');Click to view results
epoch: 0, batch: 1/10 time: 0.0027 ( 0.0027) loss: 0.6369 ( 0.6369) acc: 0.69 ( 0.69)
epoch: 0, batch: 2/10 time: 0.0009 ( 0.0035) loss: 0.7174 ( 0.6772) acc: 0.47 ( 0.58)
epoch: 0, batch: 3/10 time: 0.0005 ( 0.0041) loss: 0.6533 ( 0.6692) acc: 0.69 ( 0.61)
epoch: 0, batch: 4/10 time: 0.0003 ( 0.0043) loss: 0.6271 ( 0.6587) acc: 0.81 ( 0.66)
epoch: 0, batch: 5/10 time: 0.0002 ( 0.0046) loss: 0.7135 ( 0.6696) acc: 0.56 ( 0.64)
epoch: 0, batch: 6/10 time: 0.0002 ( 0.0048) loss: 0.7318 ( 0.6800) acc: 0.47 ( 0.61)
epoch: 0, batch: 7/10 time: 0.0002 ( 0.0050) loss: 0.6610 ( 0.6773) acc: 0.62 ( 0.62)
epoch: 0, batch: 8/10 time: 0.0002 ( 0.0052) loss: 0.6733 ( 0.6768) acc: 0.56 ( 0.61)
epoch: 0, batch: 9/10 time: 0.0002 ( 0.0054) loss: 0.6459 ( 0.6734) acc: 0.62 ( 0.61)
epoch: 0, batch: 10/10 time: 0.0002 ( 0.0056) loss: 0.6674 ( 0.6729) acc: 0.67 ( 0.62)
test epoch 0 test loss: 0.6444 test acc: 0.61
epoch: 1, batch: 1/10 time: 0.0003 ( 0.0003) loss: 0.6504 ( 0.6504) acc: 0.59 ( 0.59)
epoch: 1, batch: 2/10 time: 0.0002 ( 0.0005) loss: 0.6778 ( 0.6641) acc: 0.53 ( 0.56)
epoch: 1, batch: 3/10 time: 0.0002 ( 0.0007) loss: 0.6139 ( 0.6474) acc: 0.81 ( 0.65)
epoch: 1, batch: 4/10 time: 0.0002 ( 0.0009) loss: 0.6330 ( 0.6438) acc: 0.62 ( 0.64)
epoch: 1, batch: 5/10 time: 0.0002 ( 0.0011) loss: 0.6485 ( 0.6447) acc: 0.59 ( 0.63)
epoch: 1, batch: 6/10 time: 0.0002 ( 0.0014) loss: 0.5836 ( 0.6345) acc: 0.72 ( 0.65)
epoch: 1, batch: 7/10 time: 0.0003 ( 0.0016) loss: 0.7030 ( 0.6443) acc: 0.47 ( 0.62)
epoch: 1, batch: 8/10 time: 0.0002 ( 0.0019) loss: 0.6516 ( 0.6452) acc: 0.62 ( 0.62)
epoch: 1, batch: 9/10 time: 0.0002 ( 0.0021) loss: 0.6039 ( 0.6406) acc: 0.81 ( 0.64)
epoch: 1, batch: 10/10 time: 0.0002 ( 0.0023) loss: 0.6084 ( 0.6381) acc: 0.71 ( 0.65)
test epoch 1 test loss: 0.6191 test acc: 0.68
epoch: 2, batch: 1/10 time: 0.0003 ( 0.0003) loss: 0.6118 ( 0.6118) acc: 0.66 ( 0.66)
epoch: 2, batch: 2/10 time: 0.0002 ( 0.0005) loss: 0.6200 ( 0.6159) acc: 0.66 ( 0.66)
epoch: 2, batch: 3/10 time: 0.0002 ( 0.0008) loss: 0.6178 ( 0.6165) acc: 0.69 ( 0.67)
epoch: 2, batch: 4/10 time: 0.0002 ( 0.0010) loss: 0.6456 ( 0.6238) acc: 0.62 ( 0.66)
epoch: 2, batch: 5/10 time: 0.0002 ( 0.0012) loss: 0.6146 ( 0.6219) acc: 0.69 ( 0.66)
epoch: 2, batch: 6/10 time: 0.0008 ( 0.0021) loss: 0.5955 ( 0.6175) acc: 0.78 ( 0.68)
epoch: 2, batch: 7/10 time: 0.0006 ( 0.0026) loss: 0.6391 ( 0.6206) acc: 0.59 ( 0.67)
epoch: 2, batch: 8/10 time: 0.0005 ( 0.0031) loss: 0.6150 ( 0.6199) acc: 0.75 ( 0.68)
epoch: 2, batch: 9/10 time: 0.0002 ( 0.0033) loss: 0.6263 ( 0.6206) acc: 0.66 ( 0.68)
epoch: 2, batch: 10/10 time: 0.0002 ( 0.0035) loss: 0.5262 ( 0.6134) acc: 0.83 ( 0.69)
test epoch 2 test loss: 0.6032 test acc: 0.61
epoch: 3, batch: 1/10 time: 0.0002 ( 0.0002) loss: 0.5583 ( 0.5583) acc: 0.69 ( 0.69)
epoch: 3, batch: 2/10 time: 0.0002 ( 0.0004) loss: 0.5880 ( 0.5731) acc: 0.62 ( 0.66)
epoch: 3, batch: 3/10 time: 0.0002 ( 0.0005) loss: 0.6109 ( 0.5857) acc: 0.66 ( 0.66)
epoch: 3, batch: 4/10 time: 0.0002 ( 0.0007) loss: 0.6098 ( 0.5918) acc: 0.69 ( 0.66)
epoch: 3, batch: 5/10 time: 0.0002 ( 0.0009) loss: 0.6147 ( 0.5963) acc: 0.62 ( 0.66)
epoch: 3, batch: 6/10 time: 0.0002 ( 0.0010) loss: 0.6745 ( 0.6094) acc: 0.47 ( 0.62)
epoch: 3, batch: 7/10 time: 0.0002 ( 0.0012) loss: 0.5916 ( 0.6068) acc: 0.75 ( 0.64)
epoch: 3, batch: 8/10 time: 0.0002 ( 0.0013) loss: 0.6017 ( 0.6062) acc: 0.59 ( 0.64)
epoch: 3, batch: 9/10 time: 0.0002 ( 0.0015) loss: 0.5960 ( 0.6051) acc: 0.72 ( 0.65)
epoch: 3, batch: 10/10 time: 0.0002 ( 0.0017) loss: 0.5997 ( 0.6046) acc: 0.71 ( 0.65)
test epoch 3 test loss: 0.5860 test acc: 0.70
epoch: 4, batch: 1/10 time: 0.0005 ( 0.0005) loss: 0.5503 ( 0.5503) acc: 0.78 ( 0.78)
epoch: 4, batch: 2/10 time: 0.0003 ( 0.0008) loss: 0.5668 ( 0.5586) acc: 0.66 ( 0.72)
epoch: 4, batch: 3/10 time: 0.0002 ( 0.0010) loss: 0.6008 ( 0.5727) acc: 0.62 ( 0.69)
epoch: 4, batch: 4/10 time: 0.0002 ( 0.0012) loss: 0.5006 ( 0.5546) acc: 0.91 ( 0.74)
epoch: 4, batch: 5/10 time: 0.0002 ( 0.0015) loss: 0.6358 ( 0.5709) acc: 0.53 ( 0.70)
epoch: 4, batch: 6/10 time: 0.0002 ( 0.0017) loss: 0.6629 ( 0.5862) acc: 0.56 ( 0.68)
epoch: 4, batch: 7/10 time: 0.0002 ( 0.0019) loss: 0.5556 ( 0.5818) acc: 0.75 ( 0.69)
epoch: 4, batch: 8/10 time: 0.0002 ( 0.0021) loss: 0.6186 ( 0.5864) acc: 0.69 ( 0.69)
epoch: 4, batch: 9/10 time: 0.0002 ( 0.0023) loss: 0.5685 ( 0.5844) acc: 0.75 ( 0.69)
epoch: 4, batch: 10/10 time: 0.0002 ( 0.0025) loss: 0.5657 ( 0.5830) acc: 0.75 ( 0.70)
test epoch 4 test loss: 0.5795 test acc: 0.73
epoch: 5, batch: 1/10 time: 0.0002 ( 0.0002) loss: 0.5589 ( 0.5589) acc: 0.78 ( 0.78)
epoch: 5, batch: 2/10 time: 0.0002 ( 0.0004) loss: 0.6664 ( 0.6127) acc: 0.53 ( 0.66)
epoch: 5, batch: 3/10 time: 0.0005 ( 0.0009) loss: 0.4933 ( 0.5729) acc: 0.81 ( 0.71)
epoch: 5, batch: 4/10 time: 0.0003 ( 0.0012) loss: 0.6069 ( 0.5814) acc: 0.66 ( 0.70)
epoch: 5, batch: 5/10 time: 0.0002 ( 0.0015) loss: 0.5761 ( 0.5803) acc: 0.66 ( 0.69)
epoch: 5, batch: 6/10 time: 0.0005 ( 0.0019) loss: 0.5079 ( 0.5683) acc: 0.78 ( 0.70)
epoch: 5, batch: 7/10 time: 0.0005 ( 0.0024) loss: 0.5951 ( 0.5721) acc: 0.75 ( 0.71)
epoch: 5, batch: 8/10 time: 0.0002 ( 0.0026) loss: 0.6346 ( 0.5799) acc: 0.75 ( 0.71)
epoch: 5, batch: 9/10 time: 0.0002 ( 0.0028) loss: 0.5220 ( 0.5735) acc: 0.75 ( 0.72)
epoch: 5, batch: 10/10 time: 0.0004 ( 0.0032) loss: 0.5858 ( 0.5744) acc: 0.75 ( 0.72)
test epoch 5 test loss: 0.5677 test acc: 0.70
epoch: 6, batch: 1/10 time: 0.0003 ( 0.0003) loss: 0.5895 ( 0.5895) acc: 0.66 ( 0.66)
epoch: 6, batch: 2/10 time: 0.0002 ( 0.0005) loss: 0.6451 ( 0.6173) acc: 0.72 ( 0.69)
epoch: 6, batch: 3/10 time: 0.0002 ( 0.0007) loss: 0.5515 ( 0.5954) acc: 0.75 ( 0.71)
epoch: 6, batch: 4/10 time: 0.0003 ( 0.0010) loss: 0.4528 ( 0.5597) acc: 0.81 ( 0.73)
epoch: 6, batch: 5/10 time: 0.0002 ( 0.0012) loss: 0.5487 ( 0.5575) acc: 0.78 ( 0.74)
epoch: 6, batch: 6/10 time: 0.0003 ( 0.0015) loss: 0.5767 ( 0.5607) acc: 0.75 ( 0.74)
epoch: 6, batch: 7/10 time: 0.0003 ( 0.0019) loss: 0.5613 ( 0.5608) acc: 0.69 ( 0.74)
epoch: 6, batch: 8/10 time: 0.0003 ( 0.0021) loss: 0.6238 ( 0.5687) acc: 0.69 ( 0.73)
epoch: 6, batch: 9/10 time: 0.0003 ( 0.0024) loss: 0.5552 ( 0.5672) acc: 0.66 ( 0.72)
epoch: 6, batch: 10/10 time: 0.0004 ( 0.0028) loss: 0.5332 ( 0.5646) acc: 0.71 ( 0.72)
test epoch 6 test loss: 0.5593 test acc: 0.73
epoch: 7, batch: 1/10 time: 0.0004 ( 0.0004) loss: 0.5747 ( 0.5747) acc: 0.59 ( 0.59)
epoch: 7, batch: 2/10 time: 0.0004 ( 0.0008) loss: 0.5637 ( 0.5692) acc: 0.78 ( 0.69)
epoch: 7, batch: 3/10 time: 0.0003 ( 0.0010) loss: 0.5043 ( 0.5476) acc: 0.75 ( 0.71)
epoch: 7, batch: 4/10 time: 0.0007 ( 0.0018) loss: 0.6288 ( 0.5679) acc: 0.66 ( 0.70)
epoch: 7, batch: 5/10 time: 0.0004 ( 0.0021) loss: 0.5684 ( 0.5680) acc: 0.75 ( 0.71)
epoch: 7, batch: 6/10 time: 0.0002 ( 0.0023) loss: 0.5038 ( 0.5573) acc: 0.78 ( 0.72)
epoch: 7, batch: 7/10 time: 0.0003 ( 0.0027) loss: 0.5472 ( 0.5558) acc: 0.75 ( 0.72)
epoch: 7, batch: 8/10 time: 0.0003 ( 0.0030) loss: 0.4556 ( 0.5433) acc: 0.88 ( 0.74)
epoch: 7, batch: 9/10 time: 0.0002 ( 0.0032) loss: 0.5868 ( 0.5481) acc: 0.66 ( 0.73)
epoch: 7, batch: 10/10 time: 0.0002 ( 0.0035) loss: 0.6593 ( 0.5567) acc: 0.62 ( 0.72)
test epoch 7 test loss: 0.5559 test acc: 0.75
epoch: 8, batch: 1/10 time: 0.0004 ( 0.0004) loss: 0.5462 ( 0.5462) acc: 0.78 ( 0.78)
epoch: 8, batch: 2/10 time: 0.0002 ( 0.0006) loss: 0.5395 ( 0.5428) acc: 0.78 ( 0.78)
epoch: 8, batch: 3/10 time: 0.0002 ( 0.0008) loss: 0.4910 ( 0.5255) acc: 0.78 ( 0.78)
epoch: 8, batch: 4/10 time: 0.0002 ( 0.0010) loss: 0.5386 ( 0.5288) acc: 0.72 ( 0.77)
epoch: 8, batch: 5/10 time: 0.0002 ( 0.0012) loss: 0.5165 ( 0.5263) acc: 0.72 ( 0.76)
epoch: 8, batch: 6/10 time: 0.0002 ( 0.0014) loss: 0.6981 ( 0.5550) acc: 0.59 ( 0.73)
epoch: 8, batch: 7/10 time: 0.0002 ( 0.0016) loss: 0.6481 ( 0.5683) acc: 0.56 ( 0.71)
epoch: 8, batch: 8/10 time: 0.0002 ( 0.0018) loss: 0.4619 ( 0.5550) acc: 0.81 ( 0.72)
epoch: 8, batch: 9/10 time: 0.0002 ( 0.0020) loss: 0.5253 ( 0.5517) acc: 0.75 ( 0.72)
epoch: 8, batch: 10/10 time: 0.0002 ( 0.0022) loss: 0.5829 ( 0.5541) acc: 0.71 ( 0.72)
test epoch 8 test loss: 0.5493 test acc: 0.70
epoch: 9, batch: 1/10 time: 0.0002 ( 0.0002) loss: 0.5264 ( 0.5264) acc: 0.72 ( 0.72)
epoch: 9, batch: 2/10 time: 0.0002 ( 0.0004) loss: 0.5313 ( 0.5289) acc: 0.72 ( 0.72)
epoch: 9, batch: 3/10 time: 0.0002 ( 0.0007) loss: 0.5436 ( 0.5338) acc: 0.69 ( 0.71)
epoch: 9, batch: 4/10 time: 0.0002 ( 0.0009) loss: 0.5267 ( 0.5320) acc: 0.75 ( 0.72)
epoch: 9, batch: 5/10 time: 0.0002 ( 0.0011) loss: 0.5339 ( 0.5324) acc: 0.69 ( 0.71)
epoch: 9, batch: 6/10 time: 0.0002 ( 0.0013) loss: 0.5624 ( 0.5374) acc: 0.69 ( 0.71)
epoch: 9, batch: 7/10 time: 0.0002 ( 0.0016) loss: 0.5758 ( 0.5429) acc: 0.75 ( 0.71)
epoch: 9, batch: 8/10 time: 0.0002 ( 0.0018) loss: 0.6656 ( 0.5582) acc: 0.66 ( 0.71)
epoch: 9, batch: 9/10 time: 0.0002 ( 0.0020) loss: 0.4790 ( 0.5494) acc: 0.84 ( 0.72)
epoch: 9, batch: 10/10 time: 0.0006 ( 0.0026) loss: 0.5030 ( 0.5459) acc: 0.79 ( 0.73)
test epoch 9 test loss: 0.5520 test acc: 0.71
epoch: 10, batch: 1/10 time: 0.0003 ( 0.0003) loss: 0.5014 ( 0.5014) acc: 0.72 ( 0.72)
epoch: 10, batch: 2/10 time: 0.0002 ( 0.0005) loss: 0.5219 ( 0.5117) acc: 0.72 ( 0.72)
epoch: 10, batch: 3/10 time: 0.0002 ( 0.0007) loss: 0.6066 ( 0.5433) acc: 0.62 ( 0.69)
epoch: 10, batch: 4/10 time: 0.0002 ( 0.0009) loss: 0.4739 ( 0.5260) acc: 0.81 ( 0.72)
epoch: 10, batch: 5/10 time: 0.0005 ( 0.0014) loss: 0.4884 ( 0.5185) acc: 0.75 ( 0.72)
epoch: 10, batch: 6/10 time: 0.0004 ( 0.0018) loss: 0.5174 ( 0.5183) acc: 0.75 ( 0.73)
epoch: 10, batch: 7/10 time: 0.0004 ( 0.0022) loss: 0.6336 ( 0.5348) acc: 0.59 ( 0.71)
epoch: 10, batch: 8/10 time: 0.0003 ( 0.0025) loss: 0.5018 ( 0.5306) acc: 0.72 ( 0.71)
epoch: 10, batch: 9/10 time: 0.0002 ( 0.0028) loss: 0.5598 ( 0.5339) acc: 0.72 ( 0.71)
epoch: 10, batch: 10/10 time: 0.0003 ( 0.0030) loss: 0.7029 ( 0.5469) acc: 0.58 ( 0.70)
test epoch 10 test loss: 0.5426 test acc: 0.73
epoch: 11, batch: 1/10 time: 0.0002 ( 0.0002) loss: 0.4767 ( 0.4767) acc: 0.84 ( 0.84)
epoch: 11, batch: 2/10 time: 0.0002 ( 0.0005) loss: 0.4931 ( 0.4849) acc: 0.81 ( 0.83)
epoch: 11, batch: 3/10 time: 0.0002 ( 0.0007) loss: 0.5163 ( 0.4954) acc: 0.75 ( 0.80)
epoch: 11, batch: 4/10 time: 0.0002 ( 0.0009) loss: 0.5133 ( 0.4999) acc: 0.69 ( 0.77)
epoch: 11, batch: 5/10 time: 0.0002 ( 0.0011) loss: 0.5337 ( 0.5066) acc: 0.72 ( 0.76)
epoch: 11, batch: 6/10 time: 0.0002 ( 0.0013) loss: 0.5320 ( 0.5108) acc: 0.72 ( 0.76)
epoch: 11, batch: 7/10 time: 0.0002 ( 0.0015) loss: 0.5900 ( 0.5222) acc: 0.62 ( 0.74)
epoch: 11, batch: 8/10 time: 0.0002 ( 0.0017) loss: 0.5231 ( 0.5223) acc: 0.69 ( 0.73)
epoch: 11, batch: 9/10 time: 0.0002 ( 0.0019) loss: 0.6666 ( 0.5383) acc: 0.66 ( 0.72)
epoch: 11, batch: 10/10 time: 0.0005 ( 0.0024) loss: 0.5417 ( 0.5386) acc: 0.71 ( 0.72)
test epoch 11 test loss: 0.5430 test acc: 0.75
epoch: 12, batch: 1/10 time: 0.0003 ( 0.0003) loss: 0.4382 ( 0.4382) acc: 0.88 ( 0.88)
epoch: 12, batch: 2/10 time: 0.0004 ( 0.0007) loss: 0.4661 ( 0.4521) acc: 0.81 ( 0.84)
epoch: 12, batch: 3/10 time: 0.0002 ( 0.0009) loss: 0.5315 ( 0.4786) acc: 0.78 ( 0.82)
epoch: 12, batch: 4/10 time: 0.0002 ( 0.0011) loss: 0.7062 ( 0.5355) acc: 0.56 ( 0.76)
epoch: 12, batch: 5/10 time: 0.0002 ( 0.0014) loss: 0.5746 ( 0.5433) acc: 0.75 ( 0.76)
epoch: 12, batch: 6/10 time: 0.0002 ( 0.0016) loss: 0.5086 ( 0.5375) acc: 0.72 ( 0.75)
epoch: 12, batch: 7/10 time: 0.0002 ( 0.0018) loss: 0.4818 ( 0.5296) acc: 0.75 ( 0.75)
epoch: 12, batch: 8/10 time: 0.0002 ( 0.0020) loss: 0.5393 ( 0.5308) acc: 0.72 ( 0.75)
epoch: 12, batch: 9/10 time: 0.0002 ( 0.0022) loss: 0.5647 ( 0.5346) acc: 0.62 ( 0.73)
epoch: 12, batch: 10/10 time: 0.0002 ( 0.0024) loss: 0.5623 ( 0.5367) acc: 0.75 ( 0.73)
test epoch 12 test loss: 0.5371 test acc: 0.71
epoch: 13, batch: 1/10 time: 0.0003 ( 0.0003) loss: 0.5402 ( 0.5402) acc: 0.69 ( 0.69)
epoch: 13, batch: 2/10 time: 0.0002 ( 0.0005) loss: 0.4711 ( 0.5056) acc: 0.75 ( 0.72)
epoch: 13, batch: 3/10 time: 0.0002 ( 0.0007) loss: 0.5807 ( 0.5307) acc: 0.66 ( 0.70)
epoch: 13, batch: 4/10 time: 0.0005 ( 0.0012) loss: 0.4489 ( 0.5102) acc: 0.88 ( 0.74)
epoch: 13, batch: 5/10 time: 0.0002 ( 0.0014) loss: 0.5490 ( 0.5180) acc: 0.66 ( 0.72)
epoch: 13, batch: 6/10 time: 0.0004 ( 0.0018) loss: 0.5164 ( 0.5177) acc: 0.75 ( 0.73)
epoch: 13, batch: 7/10 time: 0.0002 ( 0.0021) loss: 0.4889 ( 0.5136) acc: 0.78 ( 0.74)
epoch: 13, batch: 8/10 time: 0.0002 ( 0.0023) loss: 0.5421 ( 0.5172) acc: 0.72 ( 0.73)
epoch: 13, batch: 9/10 time: 0.0002 ( 0.0025) loss: 0.5951 ( 0.5258) acc: 0.66 ( 0.73)
epoch: 13, batch: 10/10 time: 0.0002 ( 0.0027) loss: 0.6380 ( 0.5345) acc: 0.67 ( 0.72)
test epoch 13 test loss: 0.5352 test acc: 0.73
epoch: 14, batch: 1/10 time: 0.0003 ( 0.0003) loss: 0.4848 ( 0.4848) acc: 0.81 ( 0.81)
epoch: 14, batch: 2/10 time: 0.0003 ( 0.0006) loss: 0.4405 ( 0.4627) acc: 0.72 ( 0.77)
epoch: 14, batch: 3/10 time: 0.0005 ( 0.0011) loss: 0.5144 ( 0.4799) acc: 0.78 ( 0.77)
epoch: 14, batch: 4/10 time: 0.0003 ( 0.0014) loss: 0.5269 ( 0.4916) acc: 0.72 ( 0.76)
epoch: 14, batch: 5/10 time: 0.0002 ( 0.0016) loss: 0.6604 ( 0.5254) acc: 0.56 ( 0.72)
epoch: 14, batch: 6/10 time: 0.0002 ( 0.0018) loss: 0.6110 ( 0.5397) acc: 0.69 ( 0.71)
epoch: 14, batch: 7/10 time: 0.0002 ( 0.0021) loss: 0.4806 ( 0.5312) acc: 0.78 ( 0.72)
epoch: 14, batch: 8/10 time: 0.0003 ( 0.0024) loss: 0.4818 ( 0.5251) acc: 0.78 ( 0.73)
epoch: 14, batch: 9/10 time: 0.0002 ( 0.0026) loss: 0.5943 ( 0.5328) acc: 0.66 ( 0.72)
epoch: 14, batch: 10/10 time: 0.0002 ( 0.0028) loss: 0.5271 ( 0.5323) acc: 0.71 ( 0.72)
test epoch 14 test loss: 0.5334 test acc: 0.73
epoch: 15, batch: 1/10 time: 0.0002 ( 0.0002) loss: 0.5533 ( 0.5533) acc: 0.72 ( 0.72)
epoch: 15, batch: 2/10 time: 0.0002 ( 0.0004) loss: 0.5033 ( 0.5283) acc: 0.69 ( 0.70)
epoch: 15, batch: 3/10 time: 0.0002 ( 0.0006) loss: 0.5100 ( 0.5222) acc: 0.72 ( 0.71)
epoch: 15, batch: 4/10 time: 0.0002 ( 0.0009) loss: 0.4975 ( 0.5160) acc: 0.78 ( 0.73)
epoch: 15, batch: 5/10 time: 0.0002 ( 0.0011) loss: 0.5635 ( 0.5255) acc: 0.69 ( 0.72)
epoch: 15, batch: 6/10 time: 0.0002 ( 0.0012) loss: 0.4336 ( 0.5102) acc: 0.84 ( 0.74)
epoch: 15, batch: 7/10 time: 0.0002 ( 0.0014) loss: 0.5944 ( 0.5222) acc: 0.62 ( 0.72)
epoch: 15, batch: 8/10 time: 0.0002 ( 0.0016) loss: 0.5018 ( 0.5197) acc: 0.81 ( 0.73)
epoch: 15, batch: 9/10 time: 0.0002 ( 0.0019) loss: 0.6449 ( 0.5336) acc: 0.62 ( 0.72)
epoch: 15, batch: 10/10 time: 0.0002 ( 0.0021) loss: 0.4810 ( 0.5295) acc: 0.79 ( 0.73)
test epoch 15 test loss: 0.5322 test acc: 0.73
epoch: 16, batch: 1/10 time: 0.0005 ( 0.0005) loss: 0.5166 ( 0.5166) acc: 0.72 ( 0.72)
epoch: 16, batch: 2/10 time: 0.0003 ( 0.0008) loss: 0.4239 ( 0.4702) acc: 0.91 ( 0.81)
epoch: 16, batch: 3/10 time: 0.0002 ( 0.0010) loss: 0.5417 ( 0.4941) acc: 0.62 ( 0.75)
epoch: 16, batch: 4/10 time: 0.0002 ( 0.0012) loss: 0.5342 ( 0.5041) acc: 0.75 ( 0.75)
epoch: 16, batch: 5/10 time: 0.0002 ( 0.0014) loss: 0.4612 ( 0.4955) acc: 0.75 ( 0.75)
epoch: 16, batch: 6/10 time: 0.0002 ( 0.0016) loss: 0.7001 ( 0.5296) acc: 0.50 ( 0.71)
epoch: 16, batch: 7/10 time: 0.0002 ( 0.0018) loss: 0.4949 ( 0.5247) acc: 0.75 ( 0.71)
epoch: 16, batch: 8/10 time: 0.0002 ( 0.0020) loss: 0.6013 ( 0.5342) acc: 0.72 ( 0.71)
epoch: 16, batch: 9/10 time: 0.0002 ( 0.0022) loss: 0.4608 ( 0.5261) acc: 0.81 ( 0.73)
epoch: 16, batch: 10/10 time: 0.0002 ( 0.0024) loss: 0.5718 ( 0.5296) acc: 0.62 ( 0.72)
test epoch 16 test loss: 0.5332 test acc: 0.79
epoch: 17, batch: 1/10 time: 0.0002 ( 0.0002) loss: 0.4943 ( 0.4943) acc: 0.81 ( 0.81)
epoch: 17, batch: 2/10 time: 0.0003 ( 0.0005) loss: 0.6689 ( 0.5816) acc: 0.66 ( 0.73)
epoch: 17, batch: 3/10 time: 0.0005 ( 0.0010) loss: 0.4056 ( 0.5230) acc: 0.84 ( 0.77)
epoch: 17, batch: 4/10 time: 0.0004 ( 0.0014) loss: 0.5235 ( 0.5231) acc: 0.69 ( 0.75)
epoch: 17, batch: 5/10 time: 0.0002 ( 0.0016) loss: 0.5725 ( 0.5330) acc: 0.66 ( 0.73)
epoch: 17, batch: 6/10 time: 0.0002 ( 0.0018) loss: 0.6354 ( 0.5501) acc: 0.66 ( 0.72)
epoch: 17, batch: 7/10 time: 0.0002 ( 0.0020) loss: 0.4868 ( 0.5410) acc: 0.75 ( 0.72)
epoch: 17, batch: 8/10 time: 0.0002 ( 0.0023) loss: 0.4939 ( 0.5351) acc: 0.75 ( 0.73)
epoch: 17, batch: 9/10 time: 0.0002 ( 0.0025) loss: 0.4727 ( 0.5282) acc: 0.72 ( 0.73)
epoch: 17, batch: 10/10 time: 0.0002 ( 0.0027) loss: 0.4837 ( 0.5248) acc: 0.88 ( 0.74)
test epoch 17 test loss: 0.5292 test acc: 0.73
epoch: 18, batch: 1/10 time: 0.0003 ( 0.0003) loss: 0.5387 ( 0.5387) acc: 0.75 ( 0.75)
epoch: 18, batch: 2/10 time: 0.0002 ( 0.0005) loss: 0.5262 ( 0.5325) acc: 0.72 ( 0.73)
epoch: 18, batch: 3/10 time: 0.0002 ( 0.0007) loss: 0.5470 ( 0.5373) acc: 0.72 ( 0.73)
epoch: 18, batch: 4/10 time: 0.0002 ( 0.0009) loss: 0.4111 ( 0.5058) acc: 0.84 ( 0.76)
epoch: 18, batch: 5/10 time: 0.0002 ( 0.0012) loss: 0.5846 ( 0.5215) acc: 0.59 ( 0.72)
epoch: 18, batch: 6/10 time: 0.0002 ( 0.0014) loss: 0.5491 ( 0.5261) acc: 0.75 ( 0.73)
epoch: 18, batch: 7/10 time: 0.0003 ( 0.0017) loss: 0.4538 ( 0.5158) acc: 0.81 ( 0.74)
epoch: 18, batch: 8/10 time: 0.0002 ( 0.0019) loss: 0.6569 ( 0.5334) acc: 0.59 ( 0.72)
epoch: 18, batch: 9/10 time: 0.0003 ( 0.0023) loss: 0.4498 ( 0.5241) acc: 0.75 ( 0.73)
epoch: 18, batch: 10/10 time: 0.0007 ( 0.0029) loss: 0.5109 ( 0.5231) acc: 0.71 ( 0.72)
test epoch 18 test loss: 0.5298 test acc: 0.73
epoch: 19, batch: 1/10 time: 0.0003 ( 0.0003) loss: 0.3752 ( 0.3752) acc: 0.94 ( 0.94)
epoch: 19, batch: 2/10 time: 0.0002 ( 0.0005) loss: 0.6385 ( 0.5068) acc: 0.62 ( 0.78)
epoch: 19, batch: 3/10 time: 0.0002 ( 0.0007) loss: 0.5200 ( 0.5112) acc: 0.72 ( 0.76)
epoch: 19, batch: 4/10 time: 0.0002 ( 0.0009) loss: 0.5394 ( 0.5183) acc: 0.72 ( 0.75)
epoch: 19, batch: 5/10 time: 0.0002 ( 0.0011) loss: 0.6300 ( 0.5406) acc: 0.62 ( 0.72)
epoch: 19, batch: 6/10 time: 0.0002 ( 0.0013) loss: 0.3921 ( 0.5159) acc: 0.84 ( 0.74)
epoch: 19, batch: 7/10 time: 0.0002 ( 0.0015) loss: 0.4118 ( 0.5010) acc: 0.84 ( 0.76)
epoch: 19, batch: 8/10 time: 0.0002 ( 0.0017) loss: 0.5767 ( 0.5105) acc: 0.66 ( 0.75)
epoch: 19, batch: 9/10 time: 0.0002 ( 0.0019) loss: 0.6589 ( 0.5270) acc: 0.56 ( 0.73)
epoch: 19, batch: 10/10 time: 0.0004 ( 0.0023) loss: 0.4414 ( 0.5204) acc: 0.79 ( 0.73)
test epoch 19 test loss: 0.5274 test acc: 0.75
epoch: 20, batch: 1/10 time: 0.0002 ( 0.0002) loss: 0.5549 ( 0.5549) acc: 0.72 ( 0.72)
epoch: 20, batch: 2/10 time: 0.0002 ( 0.0004) loss: 0.5136 ( 0.5343) acc: 0.81 ( 0.77)
epoch: 20, batch: 3/10 time: 0.0002 ( 0.0005) loss: 0.4425 ( 0.5037) acc: 0.78 ( 0.77)
epoch: 20, batch: 4/10 time: 0.0002 ( 0.0007) loss: 0.4895 ( 0.5001) acc: 0.69 ( 0.75)
epoch: 20, batch: 5/10 time: 0.0002 ( 0.0009) loss: 0.5674 ( 0.5136) acc: 0.66 ( 0.73)
epoch: 20, batch: 6/10 time: 0.0002 ( 0.0010) loss: 0.5495 ( 0.5196) acc: 0.75 ( 0.73)
epoch: 20, batch: 7/10 time: 0.0002 ( 0.0012) loss: 0.6126 ( 0.5329) acc: 0.62 ( 0.72)
epoch: 20, batch: 8/10 time: 0.0002 ( 0.0014) loss: 0.5020 ( 0.5290) acc: 0.75 ( 0.72)
epoch: 20, batch: 9/10 time: 0.0002 ( 0.0015) loss: 0.4709 ( 0.5225) acc: 0.78 ( 0.73)
epoch: 20, batch: 10/10 time: 0.0002 ( 0.0017) loss: 0.4914 ( 0.5202) acc: 0.71 ( 0.73)
test epoch 20 test loss: 0.5310 test acc: 0.79
epoch: 21, batch: 1/10 time: 0.0002 ( 0.0002) loss: 0.4043 ( 0.4043) acc: 0.81 ( 0.81)
epoch: 21, batch: 2/10 time: 0.0002 ( 0.0003) loss: 0.4541 ( 0.4292) acc: 0.78 ( 0.80)
epoch: 21, batch: 3/10 time: 0.0002 ( 0.0005) loss: 0.4782 ( 0.4455) acc: 0.84 ( 0.81)
epoch: 21, batch: 4/10 time: 0.0002 ( 0.0007) loss: 0.5035 ( 0.4600) acc: 0.78 ( 0.80)
epoch: 21, batch: 5/10 time: 0.0002 ( 0.0008) loss: 0.4548 ( 0.4590) acc: 0.75 ( 0.79)
epoch: 21, batch: 6/10 time: 0.0002 ( 0.0010) loss: 0.5077 ( 0.4671) acc: 0.78 ( 0.79)
epoch: 21, batch: 7/10 time: 0.0002 ( 0.0012) loss: 0.6386 ( 0.4916) acc: 0.62 ( 0.77)
epoch: 21, batch: 8/10 time: 0.0003 ( 0.0015) loss: 0.6509 ( 0.5115) acc: 0.62 ( 0.75)
epoch: 21, batch: 9/10 time: 0.0006 ( 0.0020) loss: 0.5014 ( 0.5104) acc: 0.78 ( 0.75)
epoch: 21, batch: 10/10 time: 0.0003 ( 0.0024) loss: 0.6384 ( 0.5202) acc: 0.62 ( 0.74)
test epoch 21 test loss: 0.5273 test acc: 0.75
epoch: 22, batch: 1/10 time: 0.0004 ( 0.0004) loss: 0.4515 ( 0.4515) acc: 0.91 ( 0.91)
epoch: 22, batch: 2/10 time: 0.0002 ( 0.0006) loss: 0.5084 ( 0.4800) acc: 0.69 ( 0.80)
epoch: 22, batch: 3/10 time: 0.0002 ( 0.0008) loss: 0.4894 ( 0.4831) acc: 0.75 ( 0.78)
epoch: 22, batch: 4/10 time: 0.0002 ( 0.0010) loss: 0.5463 ( 0.4989) acc: 0.69 ( 0.76)
epoch: 22, batch: 5/10 time: 0.0002 ( 0.0012) loss: 0.6065 ( 0.5204) acc: 0.62 ( 0.73)
epoch: 22, batch: 6/10 time: 0.0002 ( 0.0014) loss: 0.5424 ( 0.5241) acc: 0.72 ( 0.73)
epoch: 22, batch: 7/10 time: 0.0002 ( 0.0016) loss: 0.4534 ( 0.5140) acc: 0.78 ( 0.74)
epoch: 22, batch: 8/10 time: 0.0002 ( 0.0018) loss: 0.5650 ( 0.5204) acc: 0.69 ( 0.73)
epoch: 22, batch: 9/10 time: 0.0002 ( 0.0020) loss: 0.4707 ( 0.5149) acc: 0.81 ( 0.74)
epoch: 22, batch: 10/10 time: 0.0005 ( 0.0026) loss: 0.5515 ( 0.5177) acc: 0.67 ( 0.73)
test epoch 22 test loss: 0.5263 test acc: 0.75
epoch: 23, batch: 1/10 time: 0.0004 ( 0.0004) loss: 0.5447 ( 0.5447) acc: 0.69 ( 0.69)
epoch: 23, batch: 2/10 time: 0.0003 ( 0.0007) loss: 0.4289 ( 0.4868) acc: 0.81 ( 0.75)
epoch: 23, batch: 3/10 time: 0.0002 ( 0.0009) loss: 0.4433 ( 0.4723) acc: 0.88 ( 0.79)
epoch: 23, batch: 4/10 time: 0.0002 ( 0.0011) loss: 0.4462 ( 0.4658) acc: 0.84 ( 0.80)
epoch: 23, batch: 5/10 time: 0.0002 ( 0.0013) loss: 0.4906 ( 0.4707) acc: 0.69 ( 0.78)
epoch: 23, batch: 6/10 time: 0.0002 ( 0.0015) loss: 0.5551 ( 0.4848) acc: 0.69 ( 0.77)
epoch: 23, batch: 7/10 time: 0.0002 ( 0.0017) loss: 0.5468 ( 0.4937) acc: 0.78 ( 0.77)
epoch: 23, batch: 8/10 time: 0.0002 ( 0.0019) loss: 0.4368 ( 0.4866) acc: 0.84 ( 0.78)
epoch: 23, batch: 9/10 time: 0.0002 ( 0.0021) loss: 0.6938 ( 0.5096) acc: 0.59 ( 0.76)
epoch: 23, batch: 10/10 time: 0.0002 ( 0.0023) loss: 0.5981 ( 0.5164) acc: 0.58 ( 0.74)
test epoch 23 test loss: 0.5293 test acc: 0.79
epoch: 24, batch: 1/10 time: 0.0002 ( 0.0002) loss: 0.5472 ( 0.5472) acc: 0.72 ( 0.72)
epoch: 24, batch: 2/10 time: 0.0002 ( 0.0004) loss: 0.4802 ( 0.5137) acc: 0.75 ( 0.73)
epoch: 24, batch: 3/10 time: 0.0002 ( 0.0006) loss: 0.4232 ( 0.4835) acc: 0.84 ( 0.77)
epoch: 24, batch: 4/10 time: 0.0002 ( 0.0008) loss: 0.3766 ( 0.4568) acc: 0.84 ( 0.79)
epoch: 24, batch: 5/10 time: 0.0005 ( 0.0013) loss: 0.6013 ( 0.4857) acc: 0.69 ( 0.77)
epoch: 24, batch: 6/10 time: 0.0002 ( 0.0016) loss: 0.6136 ( 0.5070) acc: 0.72 ( 0.76)
epoch: 24, batch: 7/10 time: 0.0004 ( 0.0020) loss: 0.6730 ( 0.5307) acc: 0.62 ( 0.74)
epoch: 24, batch: 8/10 time: 0.0005 ( 0.0025) loss: 0.5870 ( 0.5378) acc: 0.62 ( 0.73)
epoch: 24, batch: 9/10 time: 0.0003 ( 0.0027) loss: 0.4078 ( 0.5233) acc: 0.78 ( 0.73)
epoch: 24, batch: 10/10 time: 0.0002 ( 0.0030) loss: 0.4252 ( 0.5158) acc: 0.83 ( 0.74)
test epoch 24 test loss: 0.5291 test acc: 0.79
epoch: 25, batch: 1/10 time: 0.0002 ( 0.0002) loss: 0.4816 ( 0.4816) acc: 0.81 ( 0.81)
epoch: 25, batch: 2/10 time: 0.0002 ( 0.0005) loss: 0.5668 ( 0.5242) acc: 0.72 ( 0.77)
epoch: 25, batch: 3/10 time: 0.0002 ( 0.0007) loss: 0.4185 ( 0.4890) acc: 0.81 ( 0.78)
epoch: 25, batch: 4/10 time: 0.0005 ( 0.0012) loss: 0.5083 ( 0.4938) acc: 0.75 ( 0.77)
epoch: 25, batch: 5/10 time: 0.0007 ( 0.0019) loss: 0.6036 ( 0.5158) acc: 0.62 ( 0.74)
epoch: 25, batch: 6/10 time: 0.0005 ( 0.0024) loss: 0.4225 ( 0.5002) acc: 0.88 ( 0.77)
epoch: 25, batch: 7/10 time: 0.0003 ( 0.0027) loss: 0.5083 ( 0.5014) acc: 0.75 ( 0.76)
epoch: 25, batch: 8/10 time: 0.0002 ( 0.0029) loss: 0.5569 ( 0.5083) acc: 0.69 ( 0.75)
epoch: 25, batch: 9/10 time: 0.0002 ( 0.0031) loss: 0.6239 ( 0.5212) acc: 0.59 ( 0.74)
epoch: 25, batch: 10/10 time: 0.0002 ( 0.0033) loss: 0.4306 ( 0.5142) acc: 0.79 ( 0.74)
test epoch 25 test loss: 0.5262 test acc: 0.77
epoch: 26, batch: 1/10 time: 0.0002 ( 0.0002) loss: 0.4670 ( 0.4670) acc: 0.81 ( 0.81)
epoch: 26, batch: 2/10 time: 0.0002 ( 0.0004) loss: 0.4841 ( 0.4756) acc: 0.69 ( 0.75)
epoch: 26, batch: 3/10 time: 0.0002 ( 0.0007) loss: 0.5404 ( 0.4972) acc: 0.78 ( 0.76)
epoch: 26, batch: 4/10 time: 0.0002 ( 0.0009) loss: 0.4460 ( 0.4844) acc: 0.84 ( 0.78)
epoch: 26, batch: 5/10 time: 0.0002 ( 0.0010) loss: 0.3884 ( 0.4652) acc: 0.91 ( 0.81)
epoch: 26, batch: 6/10 time: 0.0002 ( 0.0012) loss: 0.4087 ( 0.4558) acc: 0.84 ( 0.81)
epoch: 26, batch: 7/10 time: 0.0002 ( 0.0014) loss: 0.4857 ( 0.4601) acc: 0.75 ( 0.80)
epoch: 26, batch: 8/10 time: 0.0002 ( 0.0016) loss: 0.6145 ( 0.4794) acc: 0.59 ( 0.78)
epoch: 26, batch: 9/10 time: 0.0002 ( 0.0018) loss: 0.8423 ( 0.5197) acc: 0.50 ( 0.75)
epoch: 26, batch: 10/10 time: 0.0003 ( 0.0022) loss: 0.4432 ( 0.5138) acc: 0.75 ( 0.75)
test epoch 26 test loss: 0.5234 test acc: 0.75
epoch: 27, batch: 1/10 time: 0.0003 ( 0.0003) loss: 0.4600 ( 0.4600) acc: 0.81 ( 0.81)
epoch: 27, batch: 2/10 time: 0.0006 ( 0.0009) loss: 0.4459 ( 0.4529) acc: 0.75 ( 0.78)
epoch: 27, batch: 3/10 time: 0.0002 ( 0.0011) loss: 0.5786 ( 0.4948) acc: 0.66 ( 0.74)
epoch: 27, batch: 4/10 time: 0.0002 ( 0.0013) loss: 0.5808 ( 0.5163) acc: 0.66 ( 0.72)
epoch: 27, batch: 5/10 time: 0.0002 ( 0.0014) loss: 0.5137 ( 0.5158) acc: 0.75 ( 0.72)
epoch: 27, batch: 6/10 time: 0.0002 ( 0.0016) loss: 0.6957 ( 0.5458) acc: 0.66 ( 0.71)
epoch: 27, batch: 7/10 time: 0.0002 ( 0.0018) loss: 0.4941 ( 0.5384) acc: 0.75 ( 0.72)
epoch: 27, batch: 8/10 time: 0.0002 ( 0.0019) loss: 0.3765 ( 0.5181) acc: 0.88 ( 0.74)
epoch: 27, batch: 9/10 time: 0.0002 ( 0.0021) loss: 0.5164 ( 0.5179) acc: 0.78 ( 0.74)
epoch: 27, batch: 10/10 time: 0.0002 ( 0.0023) loss: 0.4564 ( 0.5132) acc: 0.79 ( 0.75)
test epoch 27 test loss: 0.5235 test acc: 0.77
epoch: 28, batch: 1/10 time: 0.0007 ( 0.0007) loss: 0.5545 ( 0.5545) acc: 0.69 ( 0.69)
epoch: 28, batch: 2/10 time: 0.0003 ( 0.0011) loss: 0.4871 ( 0.5208) acc: 0.78 ( 0.73)
epoch: 28, batch: 3/10 time: 0.0002 ( 0.0013) loss: 0.4778 ( 0.5065) acc: 0.84 ( 0.77)
epoch: 28, batch: 4/10 time: 0.0004 ( 0.0017) loss: 0.6086 ( 0.5320) acc: 0.59 ( 0.73)
epoch: 28, batch: 5/10 time: 0.0005 ( 0.0021) loss: 0.5465 ( 0.5349) acc: 0.72 ( 0.72)
epoch: 28, batch: 6/10 time: 0.0002 ( 0.0024) loss: 0.4764 ( 0.5252) acc: 0.75 ( 0.73)
epoch: 28, batch: 7/10 time: 0.0004 ( 0.0028) loss: 0.4849 ( 0.5194) acc: 0.75 ( 0.73)
epoch: 28, batch: 8/10 time: 0.0003 ( 0.0030) loss: 0.4470 ( 0.5104) acc: 0.75 ( 0.73)
epoch: 28, batch: 9/10 time: 0.0002 ( 0.0032) loss: 0.4768 ( 0.5066) acc: 0.78 ( 0.74)
epoch: 28, batch: 10/10 time: 0.0002 ( 0.0035) loss: 0.5833 ( 0.5125) acc: 0.71 ( 0.74)
test epoch 28 test loss: 0.5245 test acc: 0.77
epoch: 29, batch: 1/10 time: 0.0002 ( 0.0002) loss: 0.4398 ( 0.4398) acc: 0.81 ( 0.81)
epoch: 29, batch: 2/10 time: 0.0002 ( 0.0005) loss: 0.5747 ( 0.5073) acc: 0.69 ( 0.75)
epoch: 29, batch: 3/10 time: 0.0002 ( 0.0007) loss: 0.5527 ( 0.5224) acc: 0.72 ( 0.74)
epoch: 29, batch: 4/10 time: 0.0002 ( 0.0009) loss: 0.5642 ( 0.5329) acc: 0.72 ( 0.73)
epoch: 29, batch: 5/10 time: 0.0002 ( 0.0011) loss: 0.5575 ( 0.5378) acc: 0.72 ( 0.73)
epoch: 29, batch: 6/10 time: 0.0002 ( 0.0013) loss: 0.4969 ( 0.5310) acc: 0.78 ( 0.74)
epoch: 29, batch: 7/10 time: 0.0002 ( 0.0015) loss: 0.4301 ( 0.5166) acc: 0.78 ( 0.75)
epoch: 29, batch: 8/10 time: 0.0004 ( 0.0019) loss: 0.4092 ( 0.5031) acc: 0.84 ( 0.76)
epoch: 29, batch: 9/10 time: 0.0002 ( 0.0021) loss: 0.4293 ( 0.4949) acc: 0.75 ( 0.76)
epoch: 29, batch: 10/10 time: 0.0002 ( 0.0023) loss: 0.6926 ( 0.5101) acc: 0.54 ( 0.74)
test epoch 29 test loss: 0.5217 test acc: 0.75Click to view results
6.4 Exercises and Projects
Exercise 6.1 Please hand write a report about the details of the math formulas for Logistic regression.
Exercise 6.2 CHOOSE ONE: Please use PyTorch to apply the LogisticRegression to one of the following datasets.
- the
irisdataset. - the dating dataset.
- the
titanicdataset.
Please in addition answer the following questions.
- What is your accuracy score?
- How many epochs do you use?
- What is the batch size do you use?
- Plot the learning curve (loss vs epochs, accuracy vs epochs).
- Analyze the bias / variance status.